NVIDIA Investor Presentation Deck
Released by
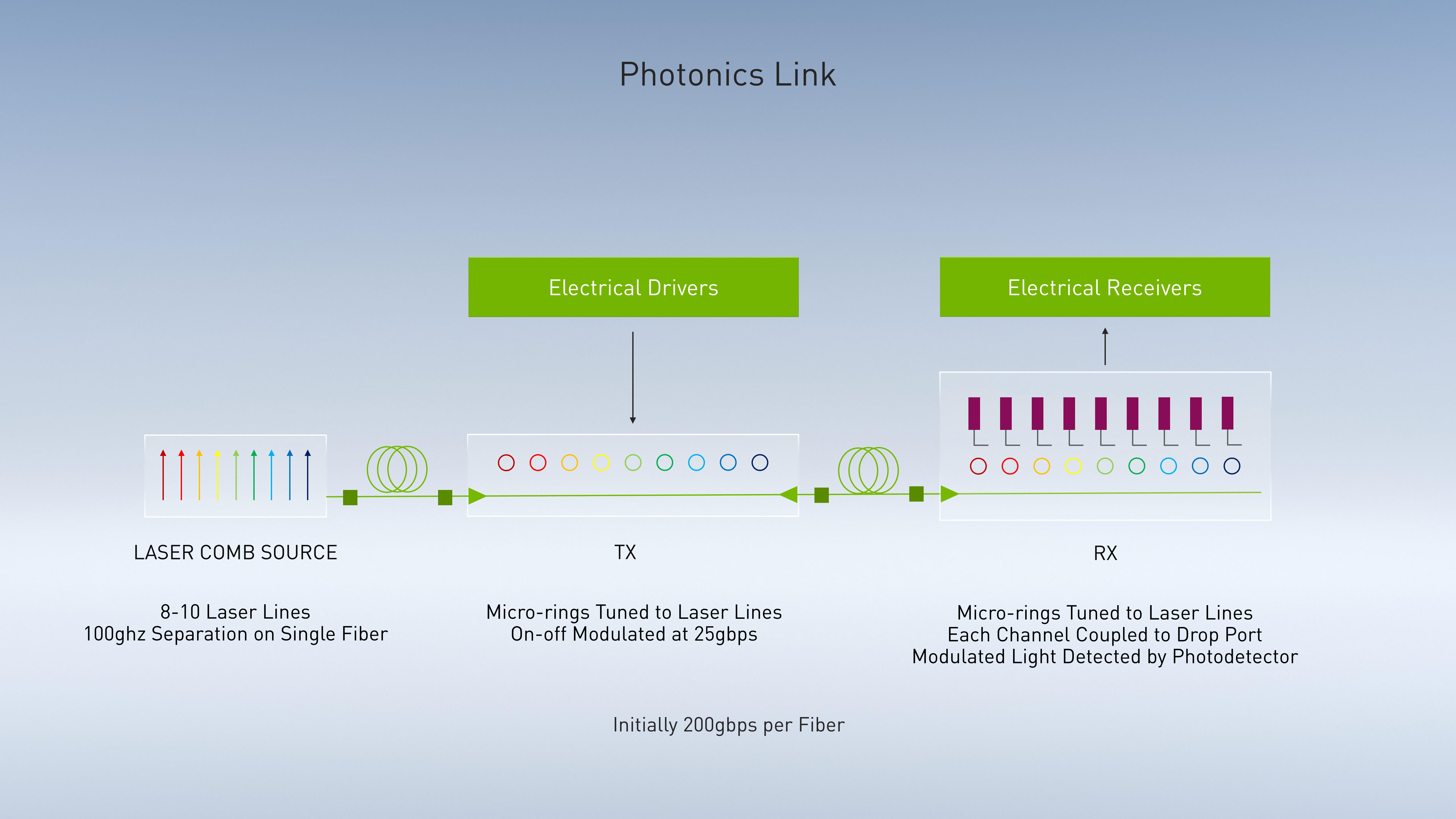
66 of 74
Slides
Transcriptions
Download to PowerPoint
Download presentation as an editable powerpoint.
Related
Released by
66 of 74
Related
Categories
Finance PresentationsTechnology PresentationsBanking PresentationsInformation Technology PresentationsOil and Energy PresentationsInternet PresentationsMining and Metals PresentationsCommunications PresentationsReal Estate PresentationsBiotechnology PresentationsAutomotive PresentationsMedical PresentationsRetail PresentationsEnergy Presentations